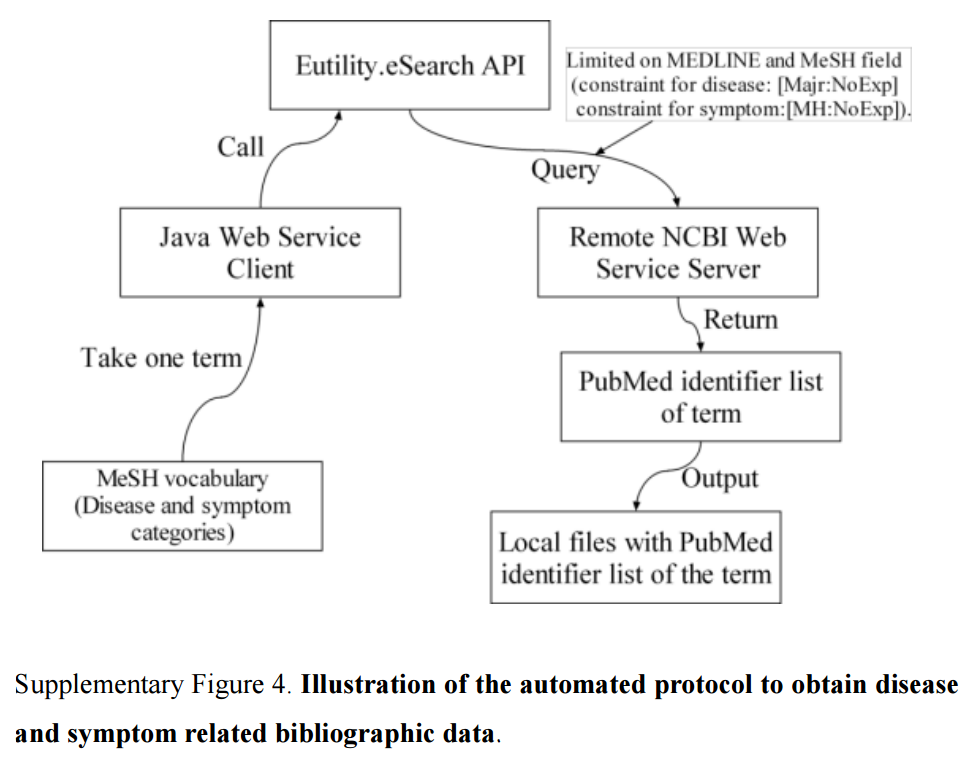
|
|
|
Project:
Rephetio: Repurposing drugs on a hetnet [rephetio]
Publication:
Human symptoms–disease network
|
Status:
Completed
Labels
resource
Views
383
Topics
Referenced by
Cite this as
Leo Brueggeman, Daniel Himmelstein (2015) Human Symptom Disease Network-MeSH ID Matching. Thinklab. doi:10.15363/thinklab.d52
License
Share
|