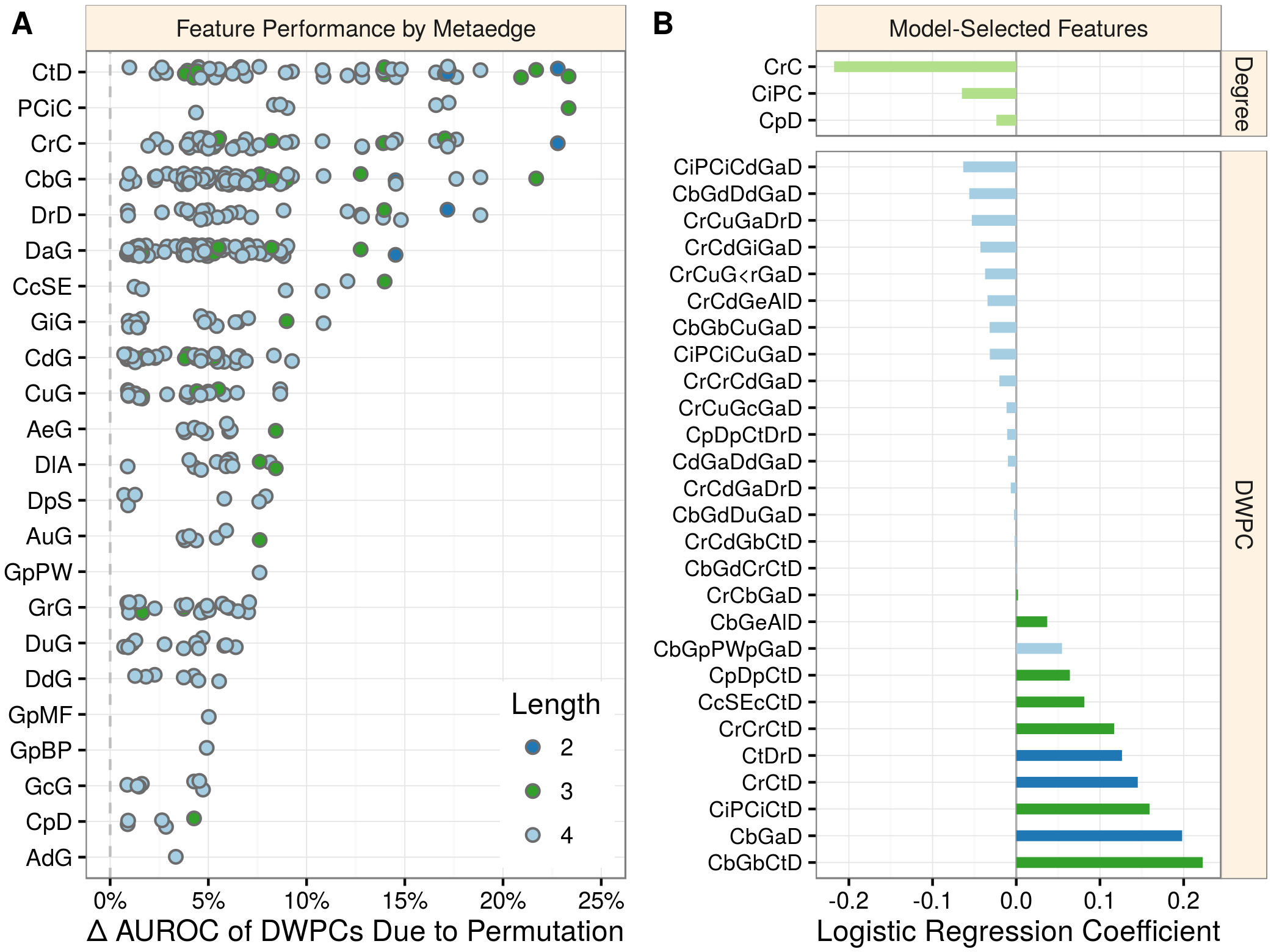
|
|
|
|
Status:
Open
Views
126
Topics
Referenced by
Cite this as
Daniel Himmelstein (2016) Our hetnet edge prediction methodology: the modeling framework for Project Rephetio. Thinklab. doi:10.15363/thinklab.d210
License
Share
|